{kind=link}

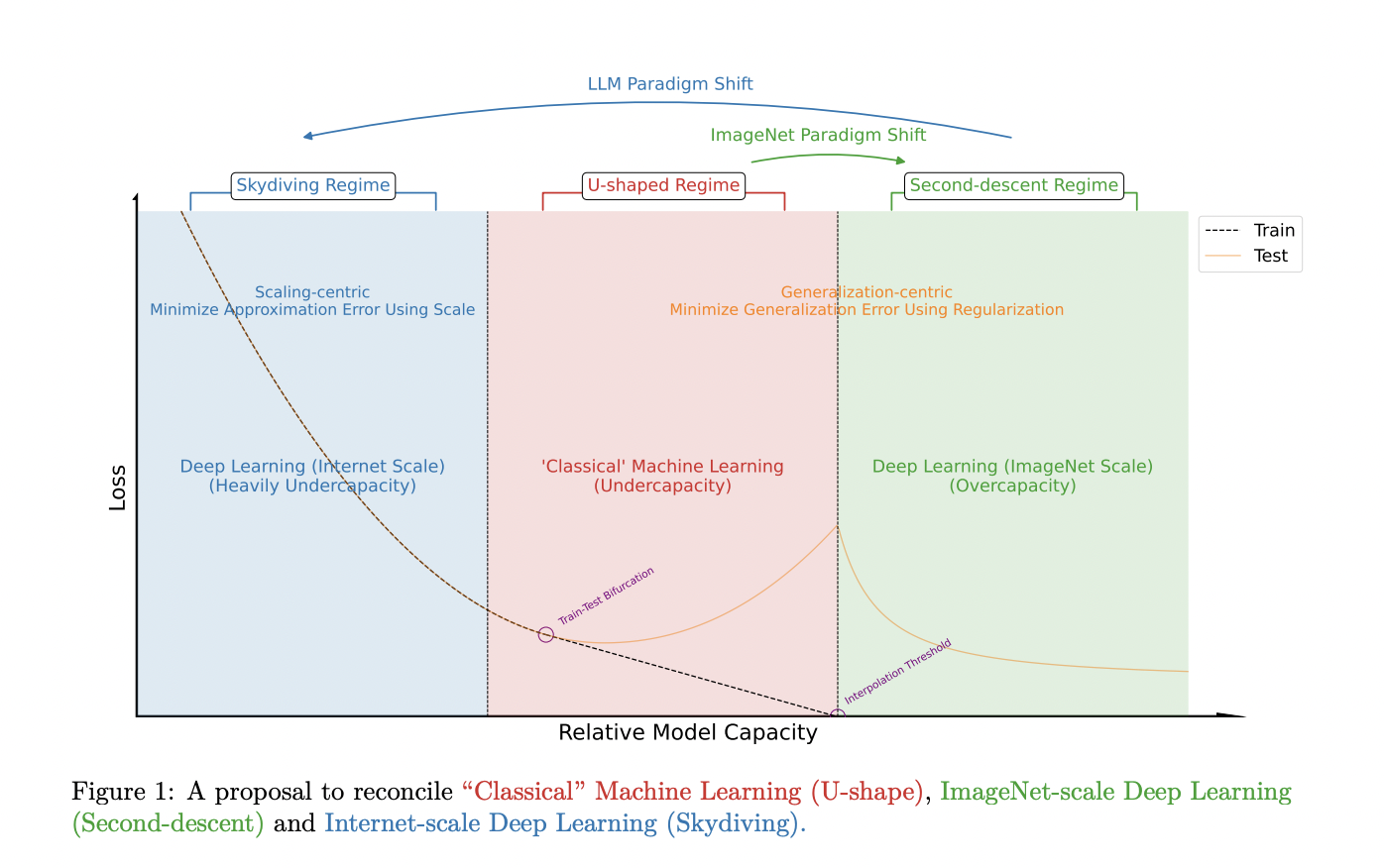
Large language models (LLMs) have gained significant attention in machine learning, shifting the focus from optimizing generalization on small datasets to reducing approximation error on massive text corpora. This paradigm shift presents researchers with new challenges in model development and training methodologies. The primary objective has evolved from preventing overfitting through regularization techniques to effectively scaling up models to consume vast amounts of data. Researchers now face the challenge of balancing computational constraints with the need for improved performance on downstream tasks. This shift necessitates a reevaluation of traditional approaches and the development of robust strategies to harness the power of large-scale language pretraining while addressing the limitations imposed by available computing resources.
The shift from a generalization-centric paradigm to a scaling-centric paradigm in machine learning has necessitated reevaluating traditional approaches. Google DeepMind researchers have identified key differences between these paradigms, focusing on minimizing approximation error through scaling rather than reducing generalization error through regularization. This shift challenges conventional wisdom, as practices that were effective in the generalization-centric paradigm may not yield optimal results in the scaling-centric approach. The phenomenon of “scaling law crossover” further complicates matters, as techniques that enhance performance at smaller scales may not translate effectively to larger ones. To mitigate these challenges, researchers propose developing new principles and methodologies to guide scaling efforts and effectively compare models at unprecedented scales where conducting multiple experiments is often infeasible.
Machine learning aims to develop functions capable of making accurate predictions on unseen data by understanding the underlying structure of the data. This process involves minimizing the test loss on unseen data while learning from a training set. The test error can be decomposed into the generalization gap and the approximation error (training error).
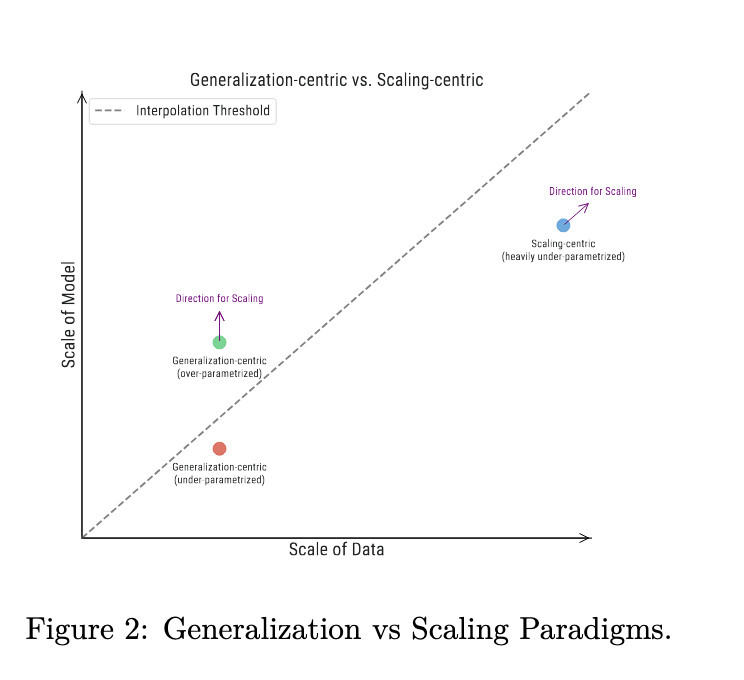
Two distinct paradigms have emerged in machine learning, differentiated by the relative and absolute scales of data and models:

1. The generalization-centric paradigm, which operates with relatively small data scales, is further divided into two sub-paradigms:
a) The classical bias-variance trade-off regime, where model capacity is intentionally constrained.
b) The modern over-parameterized regime, where model scale significantly surpasses data scale.
2. The scaling-centric paradigm, characterized by large data and model scales, with data scale exceeding model scale.
These paradigms present different challenges and require distinct approaches to optimize model performance and achieve desired outcomes.
The proposed method employs a decoder-only transformer architecture trained on the C4 dataset, utilizing the NanoDO codebase. Key architectural features include Rotary Positional Embedding, QK-Norm for attention computation, and untied head and embedding weights. The model uses Gelu activation with F = 4D, where D is the model dimension and F is the hidden dimension of the MLP. Attention heads are configured with a head dimension of 64, and the sequence length is set to 512.
The model’s vocabulary size is 32,101, and the total parameter count is approximately 12D²L, where L is the number of transformer layers. Most models are trained to Chinchilla optimality, using 20 × (12D²L + DV) tokens. Compute requirements are estimated using the formula F = 6ND, where F represents the number of floating-point operations.
For optimization, the method employs AdamW with β1 = 0.9, β2 = 0.95, ϵ = 1e-20, and a coupled weight decay λ = 0.1. This combination of architectural choices and optimization strategies aims to enhance the model’s performance in the scaling-centric paradigm.
In the scaling-centric paradigm, traditional regularization techniques are being reevaluated for their effectiveness. Three popular regularization methods commonly used in the generalization-centric paradigm are explicit L2 regularization and the implicit regularization effects of large learning rates and small batch sizes. These techniques have been instrumental in mitigating overfitting and reducing the gap between training and test losses in smaller-scale models.
However, in the context of large language models and the scaling-centric paradigm, the necessity of these regularization techniques is being questioned. As models operate in a regime where overfitting is less of a concern due to the vast amount of training data, the traditional benefits of regularization may no longer apply. This shift prompts researchers to reconsider the role of regularization in model training and to explore alternative approaches that may be more suitable for the scaling-centric paradigm.
The scaling-centric paradigm presents unique challenges in model comparison as traditional validation set approaches become impractical at massive scales. The phenomenon of scaling law crossover further complicates matters, as performance rankings observed at smaller scales may not hold true for larger models. This raises the critical question of how to effectively compare models when training is feasible only once at scale.
In contrast, the generalization-centric paradigm relies heavily on regularization as a guiding principle. This approach has led to insights into hyperparameter choices, weight decay effects, and the benefits of over-parameterization. It also explains the effectiveness of techniques like weight sharing in CNNs, locality, and hierarchy in neural network architectures.
However, the scaling-centric paradigm may require new guiding principles. While regularization has been crucial for understanding and improving generalization in smaller models, its role and effectiveness in large-scale language models are being reevaluated. Researchers are now challenged to develop robust methodologies and principles that can guide the development and comparison of models in this new paradigm, where traditional approaches may no longer apply.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.