{kind=link}

A critical challenge in Subjective Speech Quality Assessment (SSQA) is enabling models to generalize across diverse and unseen speech domains. General SSQA models evaluate many models in performing poorly outside their training domain, mainly because such a model is often met with cross-domain difficulty in performance, however, due to the quite distinct data characteristics and scoring systems that exist among different types of SSQA tasks including TTS, VC, and speech enhancement, it is equally challenging. Effective generalization of SSQA is necessary to ensure alignment of human perception in these fields, however, many such models remain limited to the data on which they have been trained, thus constraining them in their real-world utility in applications such as automated speech evaluation for TTS and VC systems.
Current SSQA approaches include both reference-based and model-based methods. Reference-based models evaluate quality by comparing speech samples with a reference. On the other hand, model-based methods, especially DNNs, learn directly from human-annotated datasets. Model-based SSQA has a strong potential for capturing human perception much more precisely but, at the same time, shows some very significant limitations:
To address these limitations, researchers introduce MOS-Bench, a benchmark collection that includes seven training datasets and twelve test datasets across varied speech types, languages, and sampling frequencies. In addition to MOS-Bench, SHEET is a toolkit proposed that provides a standardized workflow for training, validation, and testing of SSQA models. Such a combination of MOS-Bench with SHEET allows SSQA models to be evaluated systematically, and those specifically entail the generalization ability of models. MOS-Bench incorporates the multi-dataset approach, combining data across different sources to expand the exposure of the model to varying conditions. Besides that, a best score difference/ratio new performance metric is also introduced to provide a holistic assessment of the SSQA model’s performance on these datasets. This doesn’t just provide a framework for consistent evaluation but generalizes better as the models are brought in agreement with the variability of the real world, which is a pretty notable contribution towards SSQA.
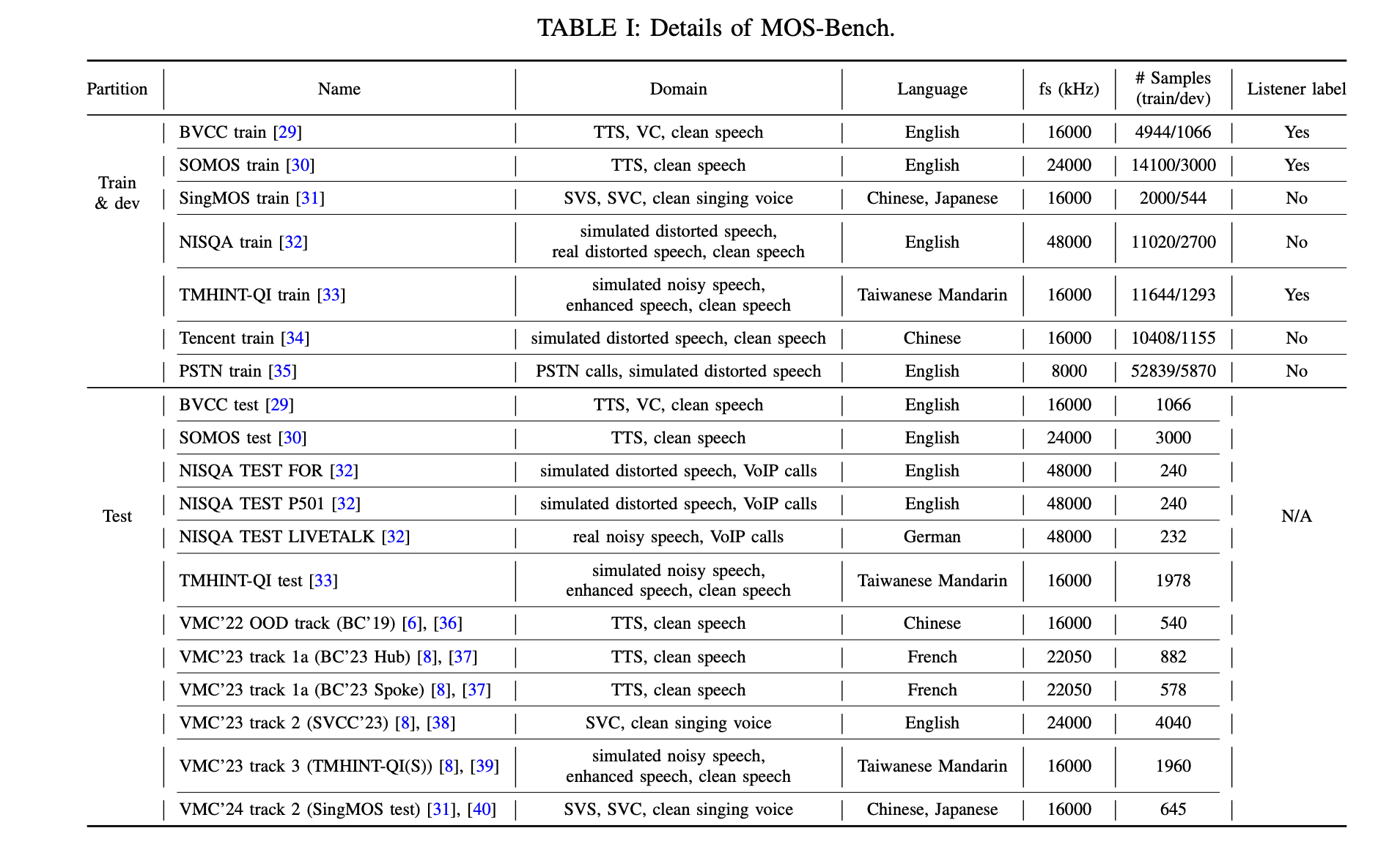
The MOS-Bench dataset collection consists of a wide range of datasets that have diversity in their sampling frequencies and listener labels to capture cross-domain variability in SSQA. Major datasets are:

- BVCC- A dataset for English that comes with samples for TTS and VC.
- SOMOS: Speech quality data about English TTS models trained on LJSpeech.
- SingMOS: A singing voice sampling dataset in Chinese and Japanese.
- NISQA: Noisy speech samples that have undergone communications over networks. Datasets are multilingual, multiple domains, and speech types for widespread training scope. MOS-Bench uses the SSL-MOS model and the modified AlignNet as backbones, utilizing SSL to learn rich feature representations. SHEET takes the SSQA process one step ahead with data processing, training, and evaluation workflows. SHEET also includes retrieval-based scoring non-parametric kNN inference to improve the faithfulness of models. In addition, hyperparameter tuning, such as batch size and optimization strategies, has been included for further improvement of model performance.
Using MOS-Bench and SHEET, both make tremendous improvements in the generalization of SSQA across synthetic and non-synthetic test sets to the point where models learn to achieve high ranks and highly faithful quality predictions even for out-of-domain data. Models trained on MOS-Bench datasets, like PSTN and NISQA, are highly robust on synthetic test sets, and the need for synthetic-focused data as previously required for generalization becomes obsolete. Further, this incorporation of visualizations firmly established that models trained on MOS-Bench captured a wide variety of data distributions and reflected better adaptability and consistency. In this regard, the introduction of these results by MOS-Bench further establishes a reliable benchmark, allowing SSQA models to apply accurate performance across different domains with greater effectiveness and applicability of automated speech quality assessment.

This methodology, through MOS-Bench and SHEET, was to challenge the generalization problem of SSQA through several datasets as well as by introducing a new metric of evaluation. Providing a reduction in dataset-specific biases and cross-domain applicability, this methodology will move the frontiers of SSQA research to make it possible for models to generalize across applications effectively. An important advancement is that cross-domain datasets have been gathered by MOS-Bench and with its standardized toolkit. Rather excitingly, the resources are now available for researchers to develop SSQA models that are robust in the presence of a variety of speech types and the presence of real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.