{kind=link}

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
The Allen Institute for AI (Ai2) today unveiled Molmo, an open-source family of state-of-the-art multimodal AI models which outpeform top proprietary rivals including OpenAI’s GPT-4o, Anthropic’s Claude 3.5 Sonnet, and Google’s Gemini 1.5 on several third-party benchmarks.
The models can therefore accept and analyze imagery uploaded to them by users, similar to the leading proprietary foundation models.
Yet, Ai2 also noted in a post on X that Molmo uses “1000x less data” than the proprietary rivals — thanks to some clever new training techniques described in greater detail below and in a technical report paper published by the Paul Allen-founded and Ali Farhadi-led company.

Ai2 says the release underscores its commitment to open research by offering high-performing models, complete with open weights and data, to the broader community — and of course, companies looking for solutions they can completely own, control, and customize.
It comes on the heels of Ai2’s release two weeks ago of another open model, OLMoE, which is a “mixture of experts” or combination of smaller models designed for cost effectiveness.
Closing the Gap Between Open and Proprietary AI
Molmo consists of four main models of different parameter sizes and capabilities:
These models achieve high performance across a range of third-party benchmarks, outpacing many proprietary alternatives. And they’re all available under permissive Apache 2.0 licenses, enabling virtually any sorts of usages for research and commercialization (e.g. enterprise grade).
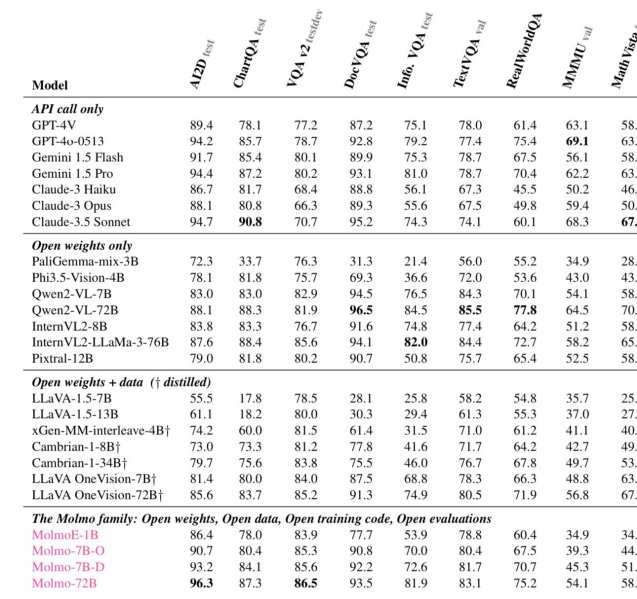
Notably, Molmo-72B leads the pack in academic evaluations, achieving the highest score on 11 key benchmarks and ranking second in user preference, closely following GPT-4o.
Vaibhav Srivastav, a machine learning developer advocate engineer at AI code repository company Hugging Face, commented on the release on X, highlighting that Molmo offers a formidable alternative to closed systems, setting a new standard for open multimodal AI.
In addition, Google DeepMind robotics researcher Ted Xiao took to X to praise the inclusion of pointing data in Molmo, which he sees as a game-changer for visual grounding in robotics.
This capability allows Molmo to provide visual explanations and interact more effectively with physical environments, a feature that is currently lacking in most other multimodal models.
The models are not only high-performing but also entirely open, allowing researchers and developers to access and build upon cutting-edge technology.
Advanced Model Architecture and Training Approach
Molmo’s architecture is designed to maximize efficiency and performance. All models use OpenAI’s ViT-L/14 336px CLIP model as the vision encoder, which processes multi-scale, multi-crop images into vision tokens.
These tokens are then projected into the language model’s input space through a multi-layer perceptron (MLP) connector and pooled for dimensionality reduction.
The language model component is a decoder-only Transformer, with options ranging from the OLMo series to the Qwen2 and Mistral series, each offering different capacities and openness levels.
The training strategy for Molmo involves two key stages:
Unlike many contemporary models, Molmo does not rely on reinforcement learning from human feedback (RLHF), focusing instead on a meticulously tuned training pipeline that updates all model parameters based on their pre-training status.
Outperforming on Key Benchmarks
The Molmo models have shown impressive results across multiple benchmarks, particularly in comparison to proprietary models.
For instance, Molmo-72B scores 96.3 on DocVQA and 85.5 on TextVQA, outperforming both Gemini 1.5 Pro and Claude 3.5 Sonnet in these categories. It further outperforms GPT-4o on AI2D (Ai2’s own benchmark, short for “A Diagram Is Worth A Dozen Images,” a dataset of 5000+ grade school science diagrams and 150,000+ rich annotations)
The models also excel in visual grounding tasks, with Molmo-72B achieving top performance on RealWorldQA, making it especially promising for applications in robotics and complex multimodal reasoning.
Open Access and Future Releases
Ai2 has made these models and datasets accessible on its Hugging Face space, with full compatibility with popular AI frameworks like Transformers.
This open access is part of Ai2’s broader vision to foster innovation and collaboration in the AI community.
Over the next few months, Ai2 plans to release additional models, training code, and an expanded version of their technical report, further enriching the resources available to researchers.
For those interested in exploring Molmo’s capabilities, a public demo and several model checkpoints are available now via Molmo’s official page.