{kind=link}

Graphical User Interfaces (GUIs) play a fundamental role in human-computer interaction, providing the medium through which users accomplish tasks across web, desktop, and mobile platforms. Automation in this field is transformative, potentially drastically improving productivity and enabling seamless task execution without requiring manual intervention. Autonomous agents capable of understanding and interacting with GUIs could revolutionize workflows, particularly in repetitive or complex task settings. However, GUIs’ inherent complexity and variability across platforms pose significant challenges. Each platform uses distinct visual layouts, action spaces, and interaction logic, making creating scalable and robust solutions difficult. Developing systems that can navigate these environments autonomously while generalizing across platforms remains an ongoing challenge for researchers in this domain.
There are many technical hurdles in GUI automation right now; one is aligning natural language instructions with the diverse visual representations of GUIs. Traditional methods often rely on textual representations, such as HTML or accessibility trees, to model GUI elements. These approaches are limited because GUIs are inherently visual, and textual abstractions fail to capture the nuances of visual design. In addition, textual representations vary between platforms, leading to fragmented data and inconsistent performance. This mismatch between the visual nature of GUIs and the textual inputs used in automation systems results in reduced scalability, longer inference times, and limited generalization. Also, most current methods are incapable of effective multimodal reasoning and grounding, which are essential for understanding complex visual environments.
Existing tools and techniques have attempted to address these challenges with mixed success. Many systems depend on closed-source models to enhance reasoning and planning capabilities. These models often use natural language communication to combine grounding and reasoning processes, but this approach introduces information loss and lacks scalability. Another common limitation is the fragmented nature of training datasets, which fail to provide comprehensive support for grounding and reasoning tasks. For instance, datasets typically emphasize either grounding or reasoning, but not both, leading to models that excel in one area while struggling in others. This division hampers the development of unified solutions for autonomous GUI interaction.
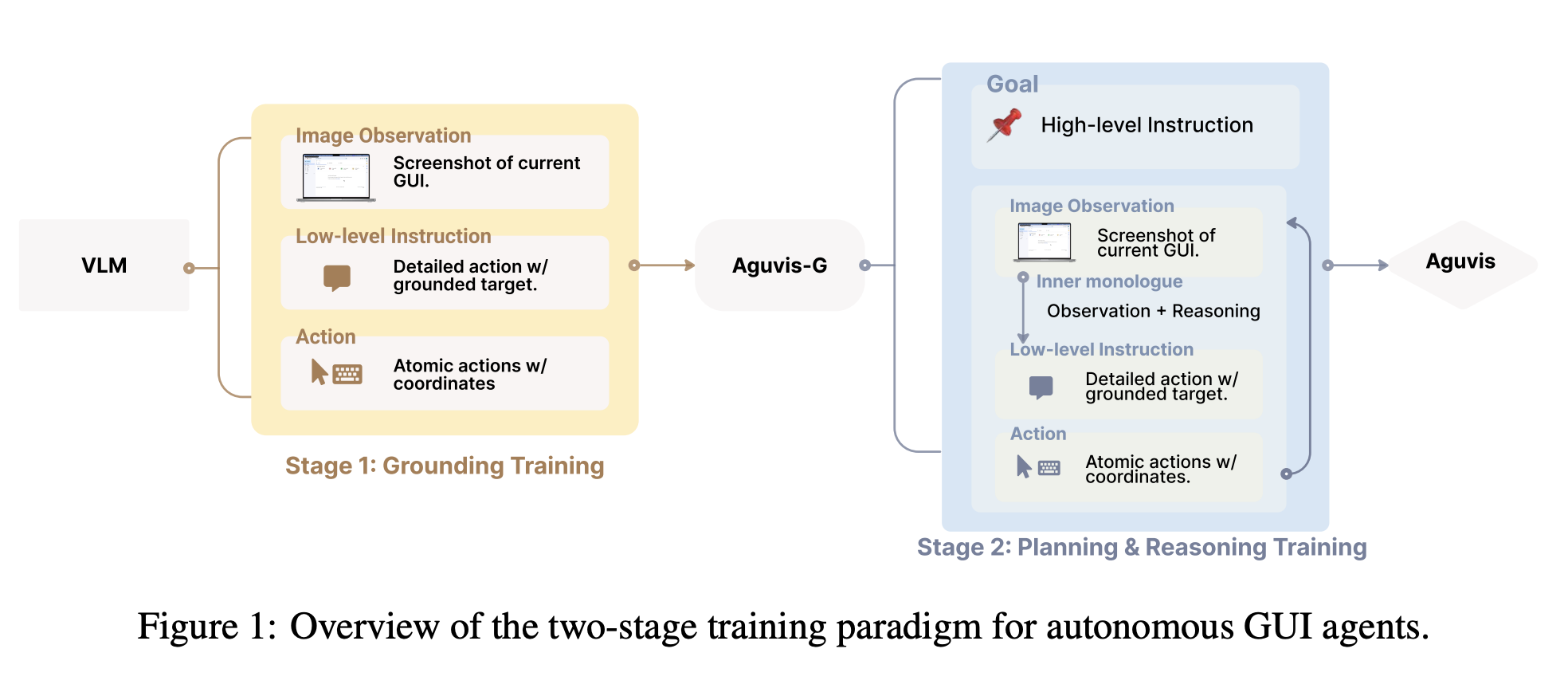
The University of Hong Kong researchers and Salesforce Research introduced AGUVIS (7B and 72B), a unified framework designed to overcome these limitations by leveraging pure vision-based observations. AGUVIS eliminates the reliance on textual representations and instead focuses on image-based inputs, aligning the model’s structure with the visual nature of GUIs. The framework includes a consistent action space across platforms, facilitating cross-platform generalization. AGUVIS integrates explicit planning and multimodal reasoning to navigate complex digital environments. The researchers constructed a large-scale dataset of GUI agent trajectories, which was used to train AGUVIS in a two-stage process. The framework’s modular architecture, which includes a pluggable action system, allows for seamless adaptation to new environments and tasks.

The AGUVIS framework employs a two-stage training paradigm to equip the model with grounding and reasoning capabilities:
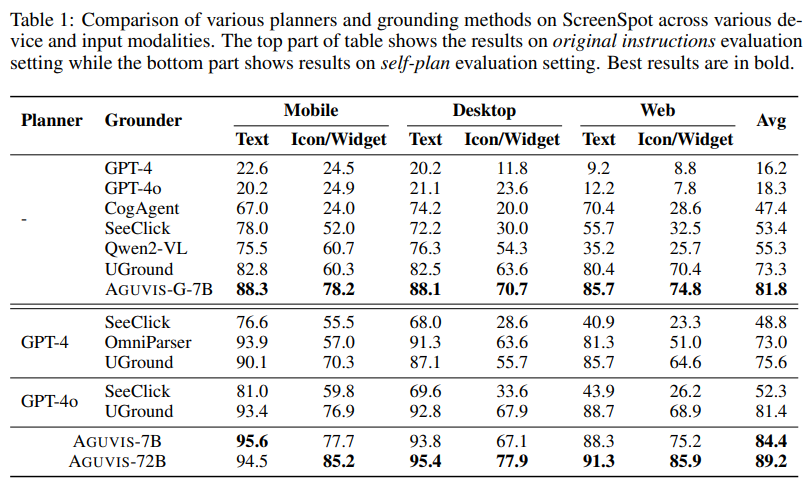
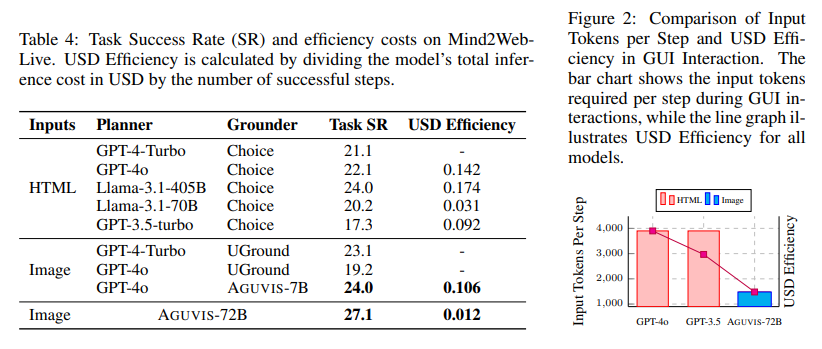
AGUVIS demonstrated great results in both offline and real-world online evaluations. In GUI grounding, the model achieved an average accuracy of 89.2, surpassing state-of-the-art methods across mobile, desktop, and web platforms. In online scenarios, AGUVIS outperformed competing models with a 51.9% improvement in step success rate during offline planning tasks. Also, the model achieved a 93% reduction in inference costs compared to GPT-4o. By focusing on visual observations and integrating a unified action space, AGUVIS sets a new benchmark for GUI automation, making it the first fully autonomous pure vision-based agent capable of completing real-world tasks without reliance on closed-source models.
Key takeaways from the research on AGUVIS in the field of GUI automation:
In conclusion, the AGUVIS framework addresses critical challenges in grounding, reasoning, and generalization in GUI automation. Its purely vision-based approach eliminates the inefficiencies associated with textual representations, while its unified action space enables seamless interaction across diverse platforms. The research provides a robust solution for autonomous GUI tasks, with applications ranging from productivity tools to advanced AI systems.
Check out the Paper, GitHub Page, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.